APRIL 29, 2026 · Peyton Montei
How the Sentiment-Maxxers Mogged their Way To Hackathon Glory With Entire
Last week, we sponsored our first hackathon at the Big Berlin Hack, laying a prize on the line for our side challenge, a proper nerdy bribe: a PlayStation 5, an Xbox Series X, a Nintendo Switch 2, and quite a few Apple Store Gift Cards.

Our challenge was simple. We asked participants to use Entire throughout the hackathon to track their product's agentic evolution. We received over 30 submissions. One challenge clearly rose to the top of the stack.
The Sentiment-Maxxers
The Sentiment-Maxxers built a product intelligence dashboard with an "AI marketer" workflow that helps challenger brands track how they appear in AI-generated answers. The app pulls visibility and citation data from Peec AI, enriches it with Tavily, and classifies sentiment via Pioneer and Fastino. Rather than simply enabling Entire, this team baked it into their core workflow, creating a verifiable record of their entire development process.
Their dashboard answers specific questions for growth teams, such as:
- Which prompts mention the brand?
- Which competitors appear more often?
- Which cited sources influence the model's answer?
- Which product features are getting reactions?
The Sentiment-Maxxers enabled Entire to track sessions across several coding agents, including Codex, OpenCode, Gemini CLI, and Copilot CLI. As they worked, Entire captured the prompts, sessions, and Checkpoints that defined their development context. When code was committed, they used Entire-Checkpoint trailers to link those changes to development traces on a separate entire/checkpoints/v1 branch.
Throughout their weekend hack, Entire collected 79 Checkpoints. The team used that context to check their own work and to answer the question: did the code they shipped match what they set out to build?
To answer this question, they cleverly built a GitHub Actions review step using a custom script: scripts/entire-intent-audit.mjs. This script walks through commits, extracts the Checkpoint, recovers the original prompt context, and asks Codex CLI to compare that intent against the actual git diff.
Each commit received a YES, NO, or PARTIAL verdict, which determined if their shipped AI-generated code matched the captured intent. On top of that, the audit rated each session, from insanely bad to insanely good, which the team displayed on a moodboard. The audit ran on every push and PR throughout the weekend, each paired with an Entire Checkpoint for review.
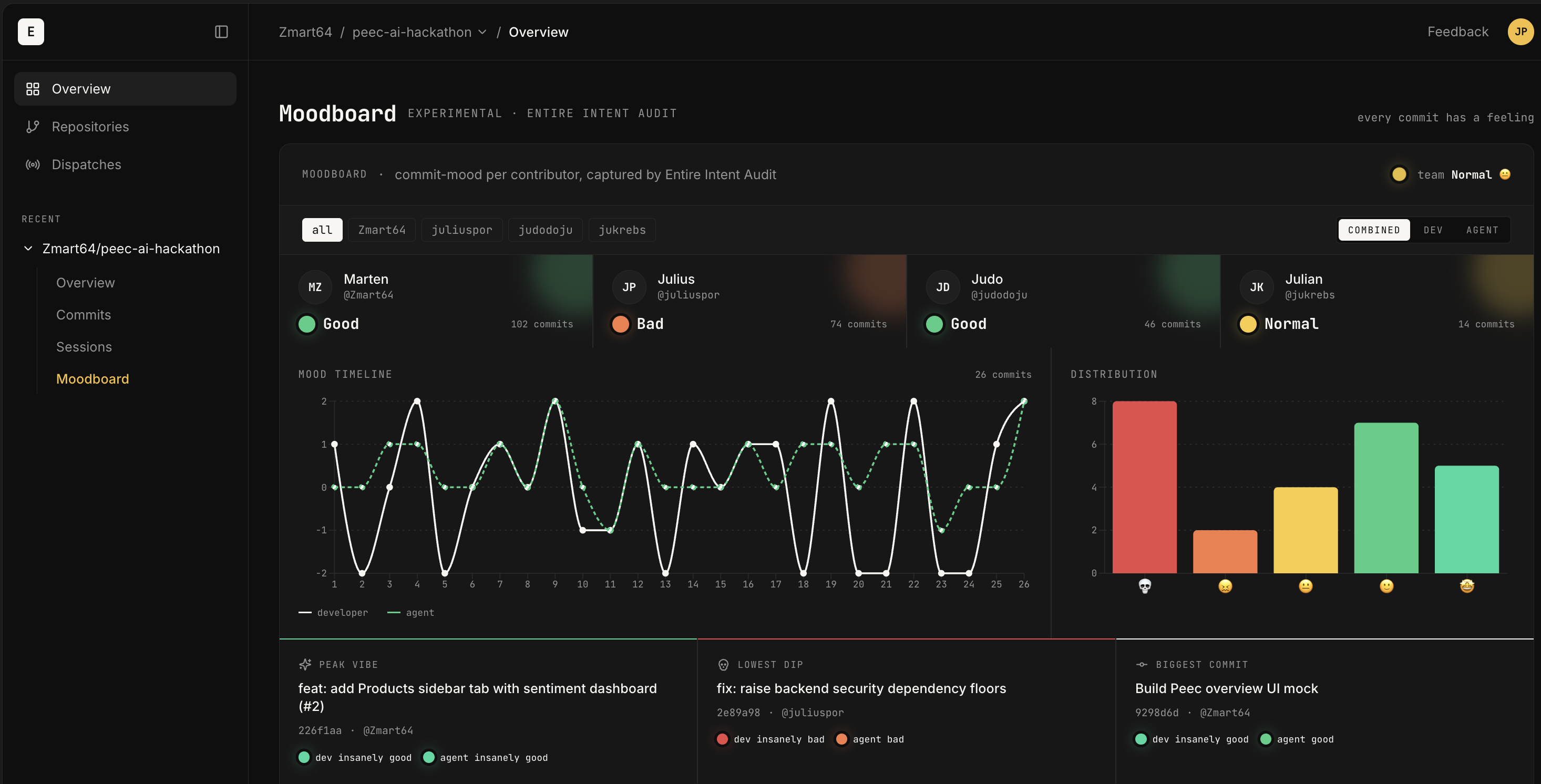
See the Work
Congratulations to Sentiment-Maxxers, who showed how Entire can give developers more confidence in adding AI-generated code to their repositories: by preserving the prompt and session context behind each change, then using that context to compare what the agent was asked to do with what actually changed.

If you want to see what they built, you can:
- Watch their full video demo.
- Explore the build history in their Entire Project Overview. This shows how those 79+ Checkpoints map to the codebase.
- Read their source code, which includes the audit script and the full implementation.
Next time you build with an AI coding agent, do not let the session disappear when the terminal closes. Capture your work with Entire so you can review, summarize, and explain the work later.